You’re three months into your SaaS build when a prospect asks if you support separate databases per customer. Your stomach drops. You built everything around a single shared schema. Refactoring now means weeks of work, delayed revenue, and a complete architecture overhaul.
Most founders face this moment. The difference between those who recover fast and those who spiral comes down to one thing: understanding multi-tenant architecture patterns before you write your first migration.
Multi-tenant SaaS architecture patterns determine how you isolate customer data, resolve tenant context, and scale your application. The five core patterns cover database isolation models, tenant identification strategies, data access controls, feature flagging per customer, and observability by tenant. Choosing the right combination early prevents costly refactoring and enables predictable scaling as your customer base grows from ten to ten thousand users.
Understanding Multi-Tenant Architecture Fundamentals
Multi-tenancy means serving multiple customers from a single application instance. Each customer is a tenant. Your code runs once, but data stays separate.
The architecture you choose affects everything. Cost per customer. Migration complexity. Security posture. Time to onboard enterprise clients.
Three forces pull your decisions:
- Isolation: How completely you separate tenant data
- Efficiency: How many resources you share across tenants
- Complexity: How much operational overhead you accept
You cannot maximize all three. Every pattern trades one for another.
Pattern One: Choosing Your Data Isolation Model
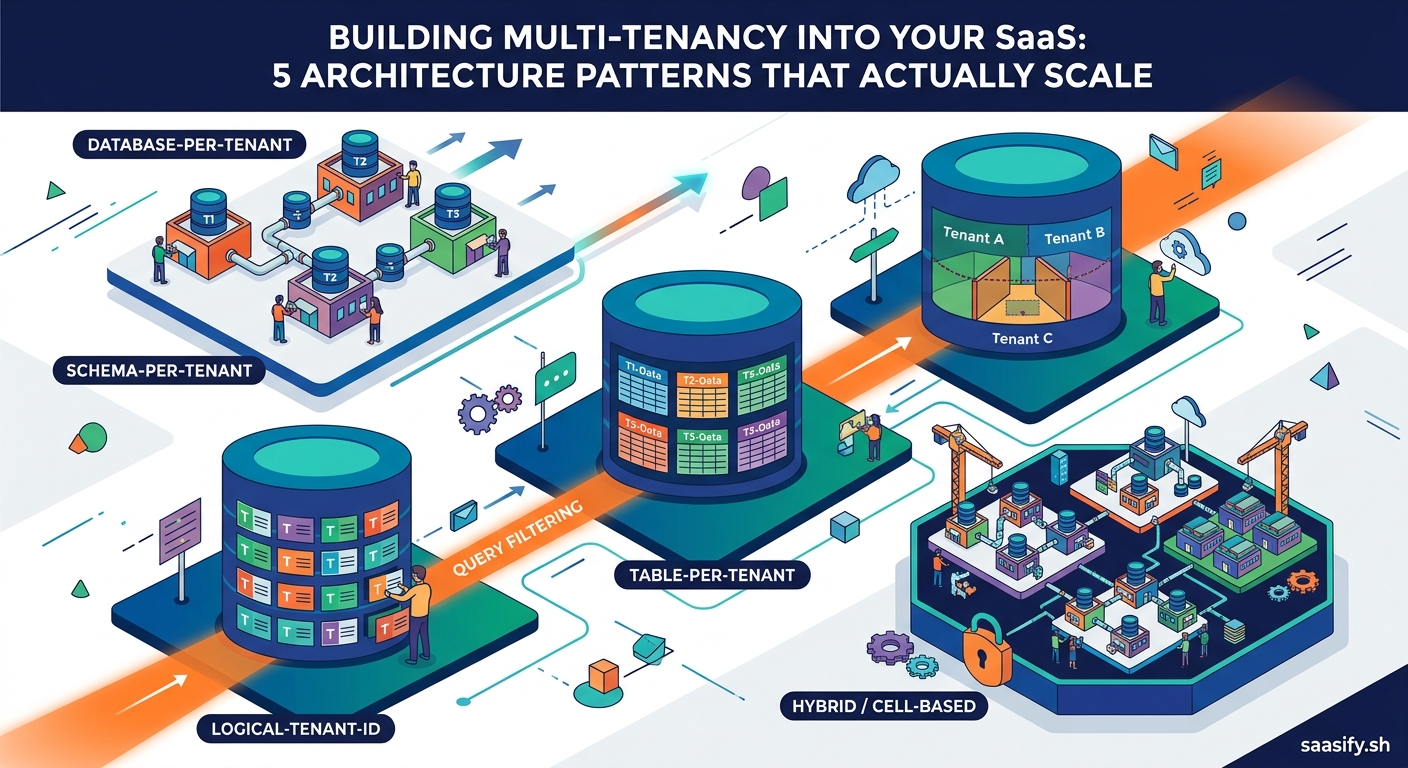
Your database strategy is the foundation. Get this wrong and everything else becomes harder.
Shared Database, Shared Schema
Every tenant’s data lives in the same tables. A tenant_id column on every row identifies ownership.
When it works: Early stage products with simple data models. Startups testing product-market fit. Applications where tenants have similar usage patterns.
The tradeoff: Lowest cost per tenant. Simplest to build. But one bad query can expose another tenant’s data. Performance tuning affects everyone. Migrations run against millions of rows instead of thousands.
Shared Database, Separate Schemas
One database, but each tenant gets their own schema. PostgreSQL schemas or MySQL databases within a single server.
When it works: Mid-market SaaS with 50 to 500 customers. Products with moderate data volumes per tenant. Teams comfortable with schema-level access controls.
The tradeoff: Better isolation than shared schema. Easier to backup or restore individual tenants. But migrations must run N times. Connection pooling gets complicated. Some tenants outgrow the shared infrastructure.
Separate Database Per Tenant
Each customer gets their own database instance. Complete physical separation.
When it works: Enterprise SaaS with compliance requirements. Products serving regulated industries. Applications where customers demand data residency guarantees.
The tradeoff: Maximum isolation. Customers can audit their own database. You can place data in specific regions. But infrastructure costs scale linearly. Migrations become orchestration challenges. Shared analytics require federation.
Start with shared schema unless you have a specific reason not to. You can always move high-value customers to isolated databases later. The reverse migration is much harder.
Pattern Two: Resolving Tenant Context in Every Request
Your application needs to know which tenant is making each request. This decision affects your URLs, authentication flow, and frontend architecture.
Here are the four common approaches:
- Subdomain-based identification:
customer1.yourapp.comvscustomer2.yourapp.com. The subdomain tells you the tenant before authentication. - Path-based identification:
yourapp.com/customer1/dashboard. The URL path contains tenant context. Works well with shared domains. - Authentication-based identification: User logs in, JWT or session contains tenant ID. No tenant information in the URL.
- Header or API key-based identification: API clients send
X-Tenant-IDheader or use tenant-specific API keys.
Most B2B SaaS products use subdomain-based identification. It feels professional. Enterprise customers expect it. You can issue separate SSL certificates per tenant if needed.
API-heavy products often use header-based identification. It keeps URLs clean. Multiple tenants can share the same API gateway. Rate limiting and routing become more flexible.
The wrong choice here creates friction. If you pick path-based routing but customers expect custom domains, you’re retrofitting DNS configuration into your onboarding flow. If you choose subdomain routing but need to support mobile apps, you’re managing tenant resolution in two different ways.
Pattern Three: Enforcing Data Isolation in Your Application Layer
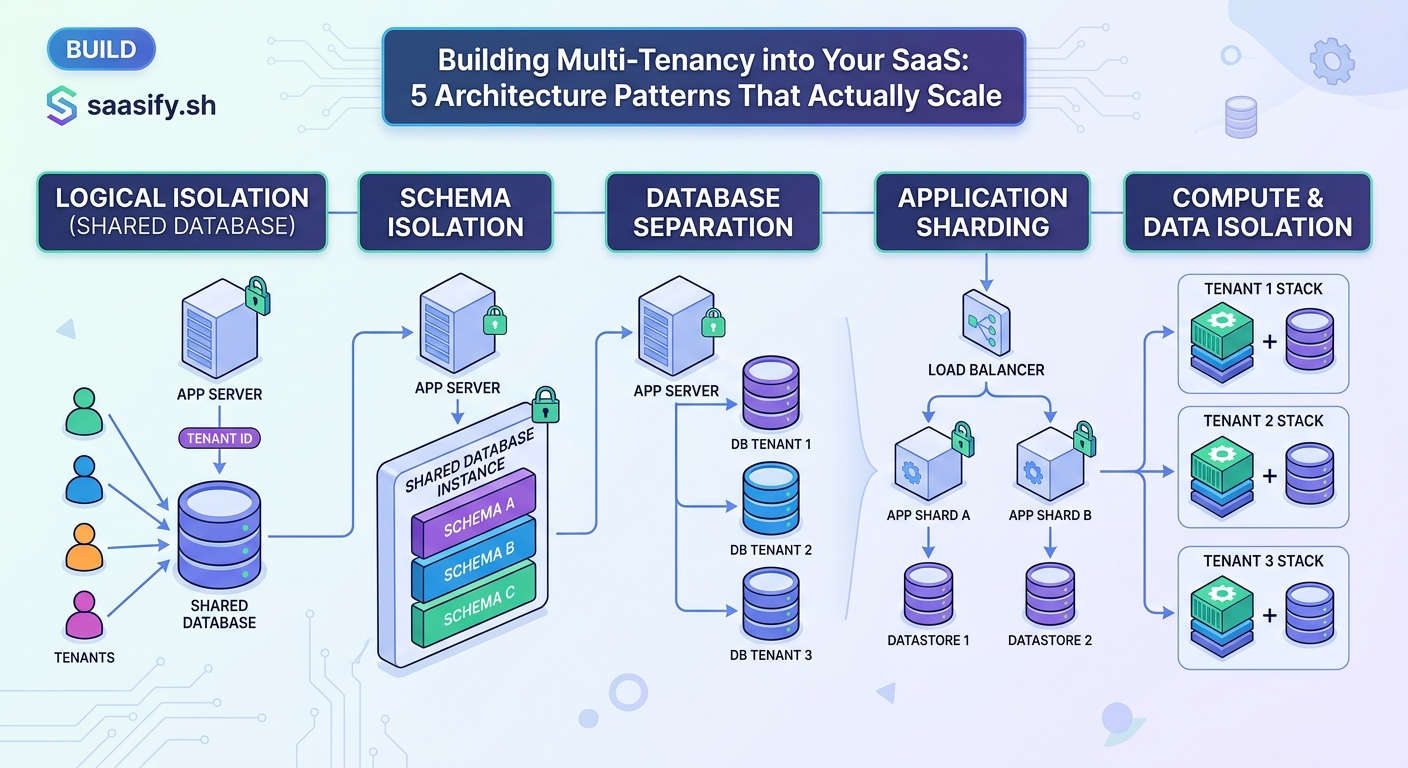
Knowing the tenant ID is not enough. You must prevent tenant A from accessing tenant B’s data, even if your database model allows it.
This pattern operates at three levels:
Query-level scoping: Every database query includes the tenant filter. Use an ORM that supports default scopes or query builders that automatically inject WHERE tenant_id = ?.
Bad
orders = db.query(“SELECT * FROM orders WHERE id = ?”, order_id)
Good
orders = db.query(“SELECT * FROM orders WHERE id = ? AND tenant_id = ?”, order_id, current_tenant_id)
Resource ownership guards: Before any update or delete operation, verify the resource belongs to the current tenant. This catches bugs where the frontend sends the wrong ID.
Middleware enforcement: Set tenant context at the request middleware level. Make it impossible for downstream code to forget the filter.
| Isolation Level | Implementation Effort | Risk of Data Leakage | Performance Impact |
|---|---|---|---|
| No enforcement | Low | Critical | None |
| Manual query filters | Medium | High | Low |
| ORM default scopes | Medium | Medium | Low |
| Row-level security | High | Low | Medium |
| Separate databases | Very High | Very Low | High |
The biggest mistakes happen in background jobs. A job processes an order but forgets to set tenant context. Suddenly emails go to the wrong customer. Reports mix data across tenants.
Always pass tenant ID explicitly to background jobs. Never rely on global state.
Pattern Four: Implementing Tenant-Aware Feature Flags
Different customers pay for different features. Your architecture must support per-tenant configuration without deploying new code.
Build a feature flag system that checks three levels:
- Global flags: Is this feature enabled for anyone?
- Plan-based flags: Does this tenant’s subscription tier include this feature?
- Tenant overrides: Did we enable this feature specifically for this customer?
The check happens on every request. Cache the results aggressively. A feature flag lookup should never hit your database directly.
can_use_feature = feature_flags.enabled?(
feature: “advanced_analytics”,
tenant: current_tenant,
user: current_user
)
This pattern enables several business capabilities:
- Launch features to a subset of customers for testing
- Upsell by showing locked features to lower-tier customers
- Provide custom capabilities to enterprise clients without branching code
- Roll back features instantly if something breaks
When you’re building a SaaS MVP in 30 days, feature flags let you ship fast without committing to every decision. You can toggle things off if customers hate them.
Pattern Five: Building Observability by Tenant
Your monitoring dashboard shows 500 errors spiking. Which customer is affected? Is it one tenant with a bad integration or a platform-wide issue?
Without tenant-tagged observability, you’re flying blind.
Tag everything with tenant ID:
- Logs: Every log line includes the tenant identifier
- Metrics: Error rates, response times, and throughput broken down by tenant
- Traces: Distributed traces carry tenant context across services
- Alerts: Notifications specify which customer is impacted
This visibility changes how you operate:
You can identify noisy neighbors before they impact other customers. You can prove SLA compliance to specific clients. You can optimize performance for your highest-value tenants. You can detect unusual usage patterns that might indicate security issues.
Set up separate dashboards for each tenant. Give enterprise customers read-only access to their own metrics. It builds trust and reduces support load.
Scaling Considerations That Actually Matter
Your architecture needs to grow with your business. Here’s what breaks first:
Connection pool exhaustion: Shared database models hit connection limits around 200 to 500 active tenants. Solution: connection pooling at the application level, read replicas, or moving large tenants to separate databases.
Migration duration: Schema changes on a 500GB shared database take hours. You cannot afford downtime. Solution: online schema change tools, blue-green deployments, or separate schemas per tenant.
Cache invalidation complexity: When tenant A updates their settings, you must not serve tenant B’s cached data. Solution: namespace your cache keys by tenant ID, use tenant-specific cache prefixes.
Background job fairness: One tenant queues 10,000 jobs and starves everyone else. Solution: separate job queues per tenant, weighted queue processing, or rate limiting on job creation.
Cost allocation: Your AWS bill is $50,000 per month but you cannot tell which customers drive the cost. Solution: tag all infrastructure with tenant ID, use separate AWS accounts for large customers, or implement usage metering.
Most of these problems do not appear until you have 50+ customers. But the architecture decisions you make at customer five determine how hard these become.
Common Architecture Mistakes and How to Avoid Them
| Mistake | Why It Happens | How to Fix It |
|---|---|---|
| Forgetting tenant filter in one query | Developer assumes context is always set | Code review checklists, ORM-level enforcement |
| Caching data without tenant key | Cache logic added before multi-tenancy | Always include tenant ID in cache keys |
| Background jobs without tenant context | Jobs triggered from requests that had context | Pass tenant ID as job parameter |
| Global rate limiting | Easier to implement initially | Implement per-tenant rate limits early |
| Shared admin accounts across tenants | Convenient for support team | Create support user accounts within each tenant |
| No tenant in error tracking | Monitoring added before multi-tenancy | Retrofit tenant tagging into all observability |
The pattern that causes the most production incidents: assuming tenant context is available globally. It works in web requests. It fails in background jobs, scheduled tasks, and webhook handlers.
Make tenant ID an explicit parameter everywhere. Your future self will thank you.
Choosing the Right Pattern Combination
You do not pick one pattern. You combine several based on your constraints.
For early-stage products (0 to 50 customers):
– Shared database, shared schema
– Subdomain-based tenant resolution
– Application-layer data isolation with ORM scopes
– Simple feature flags in your database
– Basic tenant-tagged logging
This gets you to market fast. Refactoring is manageable with 50 customers.
For growth-stage SaaS (50 to 500 customers):
– Shared database with separate schemas, or hybrid approach
– Subdomain resolution with custom domain support
– Row-level security plus application-layer checks
– Robust feature flag service
– Full observability stack with tenant dashboards
You’re optimizing for operational efficiency while maintaining isolation.
For enterprise SaaS (500+ customers or regulated industries):
– Separate databases for large customers, shared for small ones
– Flexible tenant resolution supporting multiple methods
– Database-level isolation with encryption at rest
– Advanced feature management with audit logs
– Dedicated monitoring per major customer
You’re optimizing for compliance, SLAs, and customer-specific requirements.
The transition between stages is the hard part. Build flexibility into your data access layer from day one. Wrapping all database calls behind a tenant-aware service makes future changes possible.
Migration Strategies When You Need to Change Patterns
You will need to migrate. A customer outgrows shared infrastructure. A compliance requirement forces database separation. An acquisition brings customers with different expectations.
The safest migration path:
- Build the new pattern alongside the old one: Support both shared and separate databases simultaneously. Route tenants based on a configuration flag.
- Migrate one tenant at a time: Start with internal test accounts. Move to small customers. Graduate to large customers only after proving the new pattern.
- Keep data in sync during transition: Run dual writes or use database replication. Verify data consistency before cutting over.
- Make migration reversible: Keep the ability to move tenants back if something breaks.
- Automate everything: Manual migrations do not scale past five customers.
Budget two to three months for a major architecture migration. Budget six to twelve months if you’re moving from shared schema to separate databases for hundreds of customers.
This is why getting the initial pattern right matters. Even if you cannot predict exactly where you’ll end up, understanding the tradeoffs helps you avoid the worst dead ends.
Pricing and Architecture Alignment
Your architecture should match your business model. If you’re pricing your SaaS product with a generous free tier, shared schema makes sense. If you’re targeting enterprise customers willing to pay for isolation, plan for separate databases from the start.
The disconnect happens when your sales team promises features your architecture cannot support. “Can we guarantee our data never touches other customers?” becomes a months-long engineering project if you built everything on shared tables.
Align architecture decisions with your target market before you commit code. Talk to potential customers. Understand their compliance requirements. Know which features will be table stakes versus differentiators.
Why These Patterns Matter More Than Your Tech Stack
You can implement multi-tenant architecture patterns in any language or framework. The concepts transfer from Ruby to Python to Go to JavaScript.
The patterns matter more than the tools. A well-designed multi-tenant system in Django will scale better than a poorly-designed one in Kubernetes.
That said, some technologies make certain patterns easier:
- PostgreSQL row-level security simplifies data isolation
- Redis supports tenant-namespaced caching naturally
- Modern ORMs like Prisma and SQLAlchemy have built-in tenant scoping
- Observability platforms like Datadog support custom tags out of the box
Pick tools that align with your chosen patterns. Do not let the tools dictate your architecture.
Building Multi-Tenancy Into Your Foundation
Multi-tenant architecture is not something you add later. It’s not a feature you bolt on after product-market fit.
It’s the foundation your entire SaaS business rests on. Get it right early and scaling feels natural. Get it wrong and you’ll spend months refactoring when you should be shipping features.
Start with the simplest pattern that meets your needs. Build in observability from day one. Make tenant context explicit everywhere. Plan your migration path before you need it.
Your architecture will evolve. The patterns in this guide give you a map for that evolution. Use it to make informed tradeoffs instead of discovering limitations in production.